[Python] Twitch Chat Care ( 부제: Short Text Problem in NLP)
2023년 약 한 달 동안 NLP 관련 대학교 프로젝트를 진행하게 되었다. 그 때 내가 너무 바빠서 해당 프로젝트에 신경을 쓰지 못한 탓에 좋은 결과를 내진 못했다. 다만, 발전 가능성이 있어서 이렇게 글로 남기게 된다.
NLP에는 Short Text Problem(정확히 어떤 명칭인지는 기억이 안 난다.)이라고 짧은 텍스트 처리를 따로 취급한다. 스트리밍 라이브 챗의 경우 수많은 사람이 의미 불명의 짧은 텍스트를 입력하고, 나는 그걸 분석하고 처리하고 싶었다.

첫 시도는 감정 분석이었다. 다행히 네이버에서 짧은 문장 데이터셋을 제공하고 있어서 그걸 활용해서 테스트해봤다.

랄로, 파카, 괴물쥐의 채팅 로그를 수집해 몇 가지 채팅을 직접 라벨링 한 후 테스트를 돌려봤을 때 썩 괜찮은 정확도가 나온다.
하.지.만! 정확도 0.66를 실전 투입할 수 없을 뿐더러 트위치 채팅은 상상 이상으로 기괴하다. 도대체 야벨좋이 뭐란 말인가??
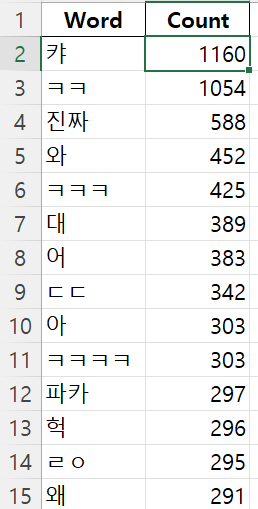

트위치 채팅 성격을 파악하기 위해 채팅 로그를 파싱후 등장횟수를 집계한 후 위처럼 나열했다. 'ㅋㅋ'와 'ㅋㅋㅋㅋㅋ'같이 단어 반복 문장을 하나로 취급하기 위해 전처리 라이브러리를 사용했다. 이를 통해 나는 채팅에서 가장 많은 빈도로 등장하는 것은 '감정표현 단어'라는 결론을 얻는다. 하지만 확정지을 수는 없다.

따라서 생각한 아이디어가 '감정표현 단어'의 발생횟수를 측정해 그 시간 대의 채팅 감정을 예측하는 것이다. 근데 이건 단순한 통계지 NLP는 아니다. 결국 마지막까지 NLP Task에 유의미한 영향을 끼치진 못했지만, 어쨌든 난 연구를 계속했다.

결국 각 텍스트의 특징을 뽑아내는 것이 가장 첫 과제라고 생각한 나는 전처리 패키지를 만들기 시작한다. 여러 시행착오와, 여러 함수를 만들고 버리며 패키지를 완성한다. (뭐가 옳고 그른지 테스트하고 쳐내는 과정이 너무 힘들었다.)
그래서 이런 식으로 패키지를 사용할 수 있게끔 했다.
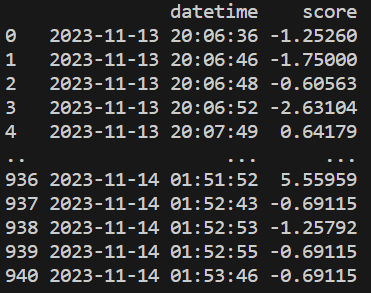
여기서부턴 잘 기억이 안나는데, 채팅 로그를 가지고 시간별 하이라이트 스코어를 매길 수 있다. 그러니까, 어떤 시간에 채팅이 가장 격했는지를 점수로 매겼던 것 같다.

마지막에는 각 단어의 발생 빈도와 횟수를 가지고 표준 편차(맞나? 기억이 안 난다.)를 구해 그 단어가 채팅에서 얼마나 비중 있는지를 관측했다. 점수가 높을 수록 채팅 전반에 사용되는 '밈'같은 성격을 지니고, 점수가 낮을 수록 특정 상황에서만 사용되는 성격을 지닌다.
그래서 종합적으로 채팅 전반에 걸친 감전 반응의 빈도, 그리고 해당 채팅에서 어떤 단어가 어떻게 쓰이는지를 파악하는 분석 패키지를 만든 셈이 되었다.
나는 이걸 발전시킨 아이디어로, 채팅을 기반으로 영상 시간대별로 태그를 붙이는 영상 편집 도우미 도구를 생각했다. 감정반응을 그래프로 나타내고, 표준편차(?) 스코어를 이용해 해당 상황이 특수한지 일반적인지를 태그로 붙인다면 편집에 굉장한 도움이 될 것이라고 생각한다.
근데 이거 만드는 와중에 트위치 한국에서 철수했다ㅋㅋㅋㅋ
외전
원래 기즈모 사용해서 실시간 NLP분석한 다음 그 결과를 기즈모로 스트리머한테 알려주려 했다.

그리고 임의의 단어를 직접 추출해 이걸로 작업을 진행하기도 했다.